
Matrix (mathematics)
Background to the schools Wikipedia
SOS Children has tried to make Wikipedia content more accessible by this schools selection. Before you decide about sponsoring a child, why not learn about different sponsorship charities first?
In mathematics, a matrix (plural matrices) is a rectangular table of elements (or entries), which may be numbers or, more generally, any abstract quantities that can be added and multiplied. Matrices are used to describe linear equations, keep track of the coefficients of linear transformations and to record data that depend on multiple parameters. Matrices are described by the field of matrix theory. Matrices can be added, multiplied, and decomposed in various ways, which also makes them a key concept in the field of linear algebra.
In this article, the entries of a matrix are real or complex numbers unless otherwise noted.

Definitions and notations
The horizontal lines in a matrix are called rows and the vertical lines are called columns. A matrix with m rows and n columns is called an m-by-n matrix (written m × n) and m and n are called its dimensions. The dimensions of a matrix are always given with the number of rows first, then the number of columns. It is commonly said that an m-by-n matrix has an order of m × n ("order" meaning size). Two matrices of the same order whose corresponding entries are equivalent are considered equal.
Almost always capital letters denote matrices with the corresponding lower-case letters with two indices representing the entries. For example, the entry of a matrix A that lies in the i-th row and the j-th column is written as ai,j and called the i,j entry or (i,j)-th entry of A. Alternative notations for that entry are A[i,j] or Ai,j. The row is always noted first, then the column. In this example, A (with no subscripts) would symbolize the entire matrix. In addition to using uppercase letters as symbols representing matrices, many authors use a special typographical style, commonly boldface upright (non-italic), to further distinguish matrices from other variables. Following this convention, A is a matrix, distinguished from A, a scalar. An alternate convention is to annotate matrices with their dimensions in small type underneath the symbol, for example, 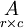 for an r-by-c matrix.
for an r-by-c matrix.
We often write 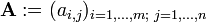 or
or 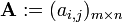 to define an m × n matrix A. In this case, the entries ai,j are defined separately for all integers 1 ≤ i ≤ m and 1 ≤ j ≤ n. In some programming languages, the numbering of rows and columns starts at zero. Texts which use any such language extensively, frequently follow that convention, so we have 0 ≤ i ≤ m-1 and 0 ≤ j ≤ n-1.
to define an m × n matrix A. In this case, the entries ai,j are defined separately for all integers 1 ≤ i ≤ m and 1 ≤ j ≤ n. In some programming languages, the numbering of rows and columns starts at zero. Texts which use any such language extensively, frequently follow that convention, so we have 0 ≤ i ≤ m-1 and 0 ≤ j ≤ n-1.
A matrix where one of the dimensions equals one is often called a vector, and interpreted as an element of real coordinate space. An m × 1 matrix (one column and m rows) is called a column vector and a 1 × n matrix (one row and n columns) is called a row vector.
Mathematical definition
An 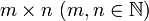 matrix
matrix  is a function
is a function 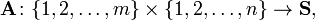 where
where 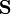 is any non- empty set.
is any non- empty set.
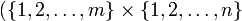 is the Cartesian product of sets
is the Cartesian product of sets 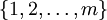 and
and 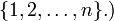
We say that matrix 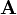 is a matrix over the set
is a matrix over the set 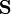 . Important thing to note is that, if we want to have matrix algebra, the set must be a ring and matrix must be a square matrix (see Square matrices and related definitions below for further explanation). Since the set of all square matrices over a ring is also a ring, matrix algebra is usually called matrix ring.
. Important thing to note is that, if we want to have matrix algebra, the set must be a ring and matrix must be a square matrix (see Square matrices and related definitions below for further explanation). Since the set of all square matrices over a ring is also a ring, matrix algebra is usually called matrix ring.
Since this article mainly considers matrices over real numbers, matrices shown here are actually functions 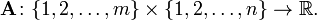
Example
The matrix
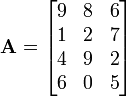 or
or 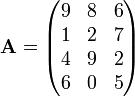
is a 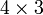 matrix. The element
matrix. The element 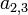 or
or ![\mathbf{A}[2,3]](../../images/139/13920.png) is 7. In terms of the mathematical definition given above, this matrix is a function
is 7. In terms of the mathematical definition given above, this matrix is a function 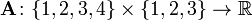 and, for example,
and, for example, 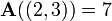 and
and 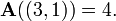
The matrix
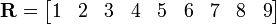
is a 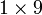 matrix, or 9-element row vector.
matrix, or 9-element row vector.
Adding and multiplying matrices
Sum
Two or more matrices of identical dimensions m and n can be added. Given m-by-n matrices A and B, their sum A+B is the m-by-n matrix computed by adding corresponding elements:

For example:

Another, much less often used notion of matrix addition is the direct sum.
Scalar multiplication
Given a matrix A and a number c, the scalar multiplication cA is computed by multiplying every element of A by the scalar c (i.e. 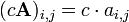 ). For example:
). For example:
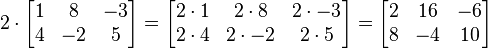
Matrix addition and scalar multiplication turn the set 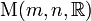 of all
of all 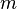 -by-
-by-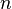 matrices with real entries into a real vector space of dimension
matrices with real entries into a real vector space of dimension 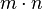 .
.
Matrix multiplication
Multiplication of two matrices is well-defined only if the number of columns of the left matrix is the same as the number of rows of the right matrix. The middle dot ( ) is not used to indicate matrix multiplication (it is used for scalar multiplication). If A is an m-by-n matrix and B is an n-by-p matrix, then their matrix product AB is the m-by-p matrix given by:
) is not used to indicate matrix multiplication (it is used for scalar multiplication). If A is an m-by-n matrix and B is an n-by-p matrix, then their matrix product AB is the m-by-p matrix given by:
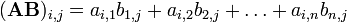
for each pair 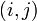 . For example:
. For example:
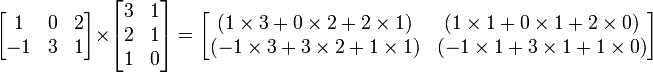
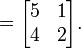
Matrix multiplication has the following properties:
- (AB)C = A(BC) for all k-by-m matrices A, m-by-n matrices B and n-by-p matrices C ("associativity").
- (A+B)C = AC+BC for all m-by-n matrices A and B and n-by-k matrices C ("right distributivity").
- C(A+B) = CA+CB for all m-by-n matrices A and B and k-by-m matrices C ("left distributivity").
Matrix multiplication is not commutative; that is, given matrices A and B and their product defined, then generally AB 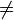 BA. It may also happen that AB is defined but BA is not defined.
BA. It may also happen that AB is defined but BA is not defined.
Besides the ordinary matrix multiplication just described, there exist other operations on matrices that can be considered forms of multiplication, such as the Hadamard product and the Kronecker product.
Linear transformations, ranks and transpose
Matrices can conveniently represent linear transformations because matrix multiplication neatly corresponds to the composition of maps, as will be described next. This same property makes them powerful data structures in high-level programming languages.
Here and in the sequel we identify Rn with the set of "columns" or n-by-1 matrices. For every linear map f : Rn → Rm there exists a unique m-by-n matrix A such that f(x) = Ax for all x in Rn. We say that the matrix A "represents" the linear map f. Now if the k-by-m matrix B represents another linear map g : Rm → Rk, then the linear map g o f is represented by BA. This follows from the above-mentioned associativity of matrix multiplication.
More generally, a linear map from an n-dimensional vector space to an m-dimensional vector space is represented by an m-by-n matrix, provided that bases have been chosen for each.
The rank of a matrix A is the dimension of the image of the linear map represented by A; this is the same as the dimension of the space generated by the rows of A, and also the same as the dimension of the space generated by the columns of A. It can also be defined without reference to linear algebra as follows: the rank of an m-by-n matrix A is the smallest number k such that A can be written as a product BC where B is an m-by-k matrix and C is a k-by-n matrix (although this is not a practical way to compute the rank).
The transpose of an m-by-n matrix A is the n-by-m matrix Atr (also sometimes written as AT or tA) formed by turning rows into columns and columns into rows, i.e. Atr[i, j] = A[j, i] for all indices i and j. If A describes a linear map with respect to two bases, then the matrix Atr describes the transpose of the linear map with respect to the dual bases, see dual space.
We have (A + B)tr = Atr + Btr and (AB)tr = Btr Atr.
A square matrix is a matrix which has the same number of rows and columns. The set of all square n-by-n matrices, together with matrix addition and matrix multiplication is a ring. Unless n = 1, this ring is not commutative.
M(n, R), the ring of real square matrices, is a real unitary associative algebra. M(n, C), the ring of complex square matrices, is a complex associative algebra.
The unit matrix or identity matrix In, with elements on the main diagonal set to 1 and all other elements set to 0, satisfies MIn = M and InN = N for any m-by-n matrix M and n-by-k matrix N. For example, if n = 3:
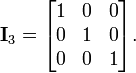
The identity matrix is the identity element in the ring of square matrices.
Invertible elements in this ring are called invertible matrices or non-singular matrices. An n by n matrix A is invertible if and only if there exists a matrix B such that
- AB = In ( = BA).
In this case, B is the inverse matrix of A, denoted by A−1. The set of all invertible n-by-n matrices forms a group (specifically a Lie group) under matrix multiplication, the general linear group.
If λ is a number and v is a non-zero vector such that Av = λv, then we call v an eigenvector of A and λ the associated eigenvalue. (Eigen means "own" in German and in Dutch.) The number λ is an eigenvalue of A if and only if A−λIn is not invertible, which happens if and only if pA(λ) = 0. Here pA(x) is the characteristic polynomial of A. This is a polynomial of degree n and has therefore n complex roots (counting multiple roots according to their multiplicity). In this sense, every square matrix has n complex eigenvalues.
The determinant of a square matrix A is the product of its n eigenvalues, but it can also be defined by the Leibniz formula. Invertible matrices are precisely those matrices with a nonzero determinant.
The Gaussian elimination algorithm is of central importance: it can be used to compute determinants, ranks and inverses of matrices and to solve systems of linear equations.
The trace of a square matrix is the sum of its diagonal entries, which equals the sum of its n eigenvalues.
Matrix exponential is defined for square matrices, using power series.
Special types of matrices
In many areas in mathematics, matrices with certain structure arise. A few important examples are
- Symmetric matrices are such that elements symmetric about the main diagonal (from the upper left to the lower right) are equal, that is,
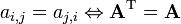 .
. - Skew-symmetric matrices are such that elements symmetric about the main diagonal are the negative of each other, that is,
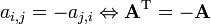 . In a skew-symmetric matrix, all diagonal elements are zero, that is,
. In a skew-symmetric matrix, all diagonal elements are zero, that is, 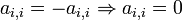 .
. - Hermitian (or self-adjoint) matrices are such that elements symmetric about the diagonal are each others complex conjugates, that is,
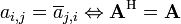 , where
, where 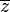 signifies the complex conjugate of a complex number
signifies the complex conjugate of a complex number 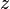 and
and 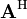 the conjugate transpose of A.
the conjugate transpose of A. - Toeplitz matrices have common elements on their diagonals, that is,
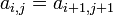 .
. - Stochastic matrices are square matrices whose rows are probability vectors; they are used to define Markov chains.
- A square matrix A is called idempotent if
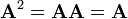 .
.
For a more extensive list see list of matrices.
Matrices in abstract algebra
If we start with a ring R, we can consider the set M(m,n, R) of all m by n matrices with entries in R. Addition and multiplication of these matrices can be defined as in the case of real or complex matrices (see above). The set M(n, R) of all square n by n matrices over R is a ring in its own right, isomorphic to the endomorphism ring of the left R- module Rn.
Similarly, if the entries are taken from a semiring S, matrix addition and multiplication can still be defined as usual. The set of all square n×n matrices over S is itself a semiring. Note that fast matrix multiplication algorithms such as the Strassen algorithm generally only apply to matrices over rings and will not work for matrices over semirings that are not rings.
If R is a commutative ring, then M(n, R) is a unitary associative algebra over R. It is then also meaningful to define the determinant of square matrices using the Leibniz formula; a matrix is invertible if and only if its determinant is invertible in R.
All statements mentioned in this article for real or complex matrices remain correct for matrices over an arbitrary field.
Matrices over a polynomial ring are important in the study of control theory.
Matrices without entries
A subtle question that is hardly ever posed is whether there is such a thing as a 3-by-0 matrix. That would be a matrix with 3 rows but without any columns, which seems absurd. However, if one wants to be able to have matrices for all linear maps between finite dimensional vector spaces, one needs such matrices, since there is nothing wrong with linear maps from a 0-dimensional space to a 3-dimensional space (in fact if the spaces are fixed there is one such map, the zero map). So one is led to admit that there is exactly one 3-by-0 matrix (which has 3×0=0 entries; not null entries but none at all). Similarly there are matrices with a positive number of columns but no rows. Moreover, even in absence of entries, one must still keep track of the number of rows and columns, since the product BC where B is the 3-by-0 matrix and C is a 0-by-4 matrix is a perfectly normal 3-by-4 matrix, all of whose 12 entries are 0 (as they are given by an empty sum). Note that this computation of BC justifies the criterion given above for the rank of a matrix in terms of possible expressions as a product: the 3-by-4 matrix with zero entries certainly has rank 0, so it should be the product of a 3-by-0 matrix and a 0-by-4 matrix. To allow and distinguish between matrices without entries, matrices should formally be defined, in a somewhat pedantic computer science style, as quadruples (A, r, c, M), where A is the set in which the entries live, r and c are the (natural) numbers of rows and columns, and M is the rectangular collection of rc elements of A (the matrix in the usual sense).
History
The study of matrices is quite old. A 3-by-3 magic square appears in Chinese literature dating from as early as 650 BC.
Matrices have a long history of application in solving linear equations. An important Chinese text from between 300 BC and AD 200, The Nine Chapters on the Mathematical Art (Jiu Zhang Suan Shu), is the first example of the use of matrix methods to solve simultaneous equations. In the seventh chapter, "Too much and not enough," the concept of a determinant first appears almost 2000 years before its publication by the Japanese mathematician Seki Kowa in 1683 and the German mathematician Gottfried Leibniz in 1693.
Magic squares were known to Arab mathematicians, possibly as early as the 7th century, when the Arabs conquered northwestern parts of the Indian subcontinent and learned Indian mathematics and astronomy, including other aspects of combinatorial mathematics. It has also been suggested that the idea came via China. The first magic squares of order 5 and 6 appear in an encyclopedia from Baghdad circa 983 AD, the Encyclopedia of the Brethren of Purity (Rasa'il Ihkwan al-Safa); simpler magic squares were known to several earlier Arab mathematicians.
After the development of the theory of determinants by Seki Kowa and Leibniz in the late 17th century, Cramer developed the theory further in the 18th century, presenting Cramer's rule in 1750. Carl Friedrich Gauss and Wilhelm Jordan developed Gauss-Jordan elimination in the 1800s.
The term "matrix" was coined in 1848 by J. J. Sylvester. Cayley, Hamilton, Grassmann, Frobenius and von Neumann are among the famous mathematicians who have worked on matrix theory.
Olga Taussky-Todd (1906-1995) made important contributions to matrix theory, using it to investigate an aerodynamic phenomenon called fluttering or aeroelasticity during WWII. She has been called "a torchbearer" for matrix theory.
Education
Matrices were traditionally taught as part of linear algebra in college, or with calculus. With the adoption of integrated mathematics texts for use in high school in the 1990s, they have been included by many such texts such as the Core-Plus Mathematics Project which are often targeted as early as the ninth grade, or earlier for honours students. They often require the use of graphing calculators such as the TI-83 which can perform complex operations such as matrix inversion very quickly.
Although most computer languages are not designed with commands or libraries for matrices, as early as the 1970s, some engineering desktop computers such as the HP 9830 had ROM cartridges to add BASIC commands for matrices. Some computer languages such as APL, were designed to manipulate matrices, and mathematical programs such as Mathematica, along with Maple, Matlab, and Octave are also used to aid computing with matrices.
Applications
Encryption
Matrices can be used to encrypt numerical data. Encryption is done by multiplying the data matrix with a key matrix. Decryption is done simply by multiplying the encrypted matrix with the inverse of the key.
Computer graphics
4×4 transformation matrices are commonly used in computer graphics. The upper left 3×3 portion of a transformation matrix is composed of the new X, Y, and Z axes of the post-transformation coordinate space.