
Random variable
About this schools Wikipedia selection
SOS believes education gives a better chance in life to children in the developing world too. To compare sponsorship charities this is the best sponsorship link.
A random variable is an abstraction of the intuitive concept of chance into the theoretical domains of mathematics, forming the foundations of probability theory and mathematical statistics.
The theory and language of random variables were formalized over the last few centuries alongside ideas of probability. Full familiarity with all the properties of random variables requires a strong background in the more recently developed concepts of measure theory, but random variables can be understood intuitively at various levels of mathematical fluency; set theory and calculus are fundamentals.
Broadly, a random variable is defined as a quantity whose values are random and to which a probability distribution is assigned. More formally, a random variable is a measurable function from a sample space to the measurable space of possible values of the variable. The formal definition of random variables places experiments involving real-valued outcomes firmly within the measure-theoretic framework and allows us to construct distribution functions of real-valued random variables.
Examples
A random variable can be used to describe the process of rolling a fair die and the possible outcomes { 1, 2, 3, 4, 5, 6 }. The most obvious representation is to take this set as the sample space, the probability measure to be uniform measure, and the function to be the identity function.
For a coin toss, a suitable space of possible outcomes is Ω = { H, T } (for heads and tails). An example random variable on this space is
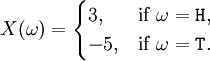
Real-valued random variables
Typically, the measurable space is the measurable space over the real numbers. In this case, let 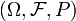 be a probability space. Then, the function
be a probability space. Then, the function 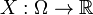 is a real-valued random variable if
is a real-valued random variable if
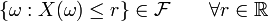
Distribution functions of random variables
Associating a cumulative distribution function (CDF) with a random variable is a generalization of assigning a value to a variable. If the CDF is a (right continuous) Heaviside step function then the variable takes on the value at the jump with probability 1. In general, the CDF specifies the probability that the variable takes on particular values.
If a random variable 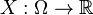 defined on the probability space
defined on the probability space 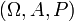 is given, we can ask questions like "How likely is it that the value of
is given, we can ask questions like "How likely is it that the value of 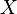 is bigger than 2?". This is the same as the probability of the event
is bigger than 2?". This is the same as the probability of the event 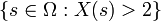 which is often written as
which is often written as 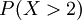 for short.
for short.
Recording all these probabilities of output ranges of a real-valued random variable X yields the probability distribution of X. The probability distribution "forgets" about the particular probability space used to define X and only records the probabilities of various values of X. Such a probability distribution can always be captured by its cumulative distribution function
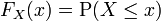
and sometimes also using a probability density function. In measure-theoretic terms, we use the random variable X to "push-forward" the measure P on Ω to a measure dF on R. The underlying probability space Ω is a technical device used to guarantee the existence of random variables, and sometimes to construct them. In practice, one often disposes of the space Ω altogether and just puts a measure on R that assigns measure 1 to the whole real line, i.e., one works with probability distributions instead of random variables.
Moments
The probability distribution of a random variable is often characterised by a small number of parameters, which also have a practical interpretation. For example, it is often enough to know what its "average value" is. This is captured by the mathematical concept of expected value of a random variable, denoted E[X]. In general, E[f(X)] is not equal to f(E[X]). Once the "average value" is known, one could then ask how far from this average value the values of X typically are, a question that is answered by the variance and standard deviation of a random variable.
Mathematically, this is known as the (generalised) problem of moments: for a given class of random variables X, find a collection {fi} of functions such that the expectation values E[fi(X)] fully characterize the distribution of the random variable X.
Functions of random variables
If we have a random variable X on Ω and a measurable function f: R → R, then Y = f(X) will also be a random variable on Ω, since the composition of measurable functions is also measurable. The same procedure that allowed one to go from a probability space (Ω, P) to (R, dFX) can be used to obtain the distribution of Y. The cumulative distribution function of Y is
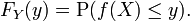
Example 1
Let X be a real-valued, continuous random variable and let Y = X2. Then,
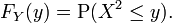
If y < 0, then P(X2 ≤ y) = 0, so

If y ≥ 0, then
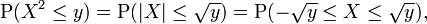
so
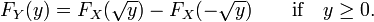
Example 2
Suppose 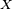 is a random variable with a cumulative distribution
is a random variable with a cumulative distribution
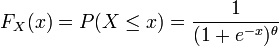
where 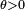 is a fixed parameter. Consider the random variable
is a fixed parameter. Consider the random variable 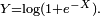 Then,
Then,
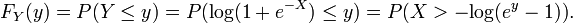
The last expression can be calculated in terms of the cumulative distribution of 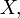 so
so
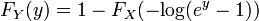
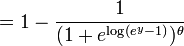
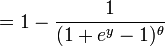
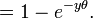
Equivalence of random variables
There are several different senses in which random variables can be considered to be equivalent. Two random variables can be equal, equal almost surely, equal in mean, or equal in distribution.
In increasing order of strength, the precise definition of these notions of equivalence is given below.
Equality in distribution
Two random variables X and Y are equal in distribution if they have the same distribution functions:
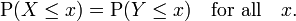
Two random variables having equal moment generating functions have the same distribution. This provides, for example, a useful method of checking equality of certain functions of iidrv's.
To be equal in distribution, random variables need not be defined on the same probability space. The notion of equivalence in distribution is associated to the following notion of distance between probability distributions,
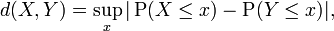
which is the basis of the Kolmogorov-Smirnov test.
Equality in mean
Two random variables X and Y are equal in p-th mean if the pth moment of |X − Y| is zero, that is,
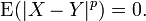
Equality in pth mean implies equality in qth mean for all q<p. As in the previous case, there is a related distance between the random variables, namely
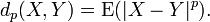
Almost sure equality
Two random variables X and Y are equal almost surely if, and only if, the probability that they are different is zero:
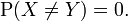
For all practical purposes in probability theory, this notion of equivalence is as strong as actual equality. It is associated to the following distance:
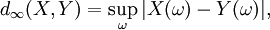
where 'sup' in this case represents the essential supremum in the sense of measure theory.
Equality
Finally, the two random variables X and Y are equal if they are equal as functions on their probability space, that is,
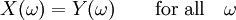
Convergence
Much of mathematical statistics consists in proving convergence results for certain sequences of random variables; see for instance the law of large numbers and the central limit theorem.
There are various senses in which a sequence (Xn) of random variables can converge to a random variable X. These are explained in the article on convergence of random variables.
Literature
- Kallenberg, O., Random Measures, 4th edition. Academic Press, New York, London; Akademie-Verlag, Berlin (1986). MR0854102 ISBN 0123949602
- Papoulis, Athanasios 1965 Probability, Random Variables, and Stochastic Processes. McGraw-Hill Kogakusha, Tokyo, 9th edition, ISBN 0-07-119981-0.