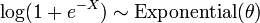Exponential distribution
Background to the schools Wikipedia
SOS Children, an education charity, organised this selection. With SOS Children you can choose to sponsor children in over a hundred countries
Probability density function |
|
Cumulative distribution function |
|
| Parameters | 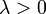 rate or inverse scale (real) rate or inverse scale (real) |
|---|---|
| Support | 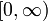 |
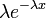 |
|
| CDF | 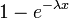 |
| Mean |  |
| Median | 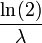 |
| Mode | 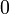 |
| Variance | 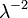 |
| Skewness | 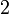 |
| Ex. kurtosis | 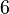 |
| Entropy | 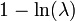 |
| MGF | 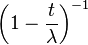 |
| CF | 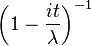 |
In probability theory and statistics, the exponential distributions are a class of continuous probability distributions. An exponential distribution arises naturally when modeling the time between independent events that happen at a constant average rate.
Characterization
Probability density function
The probability density function (pdf) of an exponential distribution has the form

where λ > 0 is a parameter of the distribution, often called the rate parameter. The distribution is supported on the interval [0,∞). If a random variable X has this distribution, we write X ~ Exponential(λ).
Cumulative distribution function
The cumulative distribution function is given by

Alternate parameterization
A commonly used alternate parameterization is to define the probability density function (pdf) of an exponential distribution as

where β > 0 is a scale parameter of the distribution and is the reciprocal of the rate parameter, λ, defined above. In this specification, β is a survival parameter in the sense that if a random variable X is the duration of time that a given biological or mechanical system M manages to survive and X ~ Exponential(β) then ![\mathbb{E}[X] = \beta](../../images/77/7760.png) . That is to say, the expected duration of survival of M is β units of time.
. That is to say, the expected duration of survival of M is β units of time.
This alternate specification is sometimes more convenient than the one given above, and some authors will use it as a standard definition. We shall not assume this alternate specification. Unfortunately this gives rise to a notational ambiguity. In general, the reader must check which of these two specifications is being used if an author writes "X ~ Exponential(λ)", since either the notation in the previous (using λ) or the notation in this section (here, using β to avoid confusion) could be intended.
Occurrence and applications
The exponential distribution occurs naturally when describing the lengths of the inter-arrival times in a homogeneous Poisson processes.
The exponential distribution may be viewed as a continuous counterpart of the geometric distribution, which describes the number of Bernoulli trials necessary for a discrete process to change state. In contrast, the exponential distribution describes the time for a continuous process to change state.
In real-world scenarios, the assumption of a constant rate (or probability per unit time) is rarely satisfied. For example, the rate of incoming phone calls differs according to the time of day. But if we focus on a time interval during which the rate is roughly constant, such as from 2 to 4 p.m. during work days, the exponential distribution can be used as a good approximate model for the time until the next phone call arrives. Similar caveats apply to the following examples which yield approximately exponentially distributed variables:
- the time until a radioactive particle decays, or the time between beeps of a geiger counter;
- the time it takes before your next telephone call
- the time until default (on payment to company debt holders) in reduced form credit risk modeling
Exponential variables can also be used to model situations where certain events occur with a constant probability per unit distance:
- the distance between mutations on a DNA strand;
- the distance between roadkill on a given street;
In queuing theory, the inter-arrival times (i.e. the times between customers entering the system) are often modeled as exponentially distributed variables. The length of a process that can be thought of as a sequence of several independent tasks is better modeled by a variable following the Erlang distribution (which is the distribution of the sum of several independent exponentially distributed variables).
Reliability theory and reliability engineering also make extensive use of the exponential distribution. Because of the memoryless property of this distribution, it is well-suited to model the constant hazard rate portion of the bathtub curve used in reliability theory. It is also very convenient because it is so easy to add failure rates in a reliability model. The exponential distribution is however not appropriate to model the overall lifetime of organisms or technical devices, because the "failure rates" here are not constant: more failures occur for very young and for very old systems.
In physics, if you observe a gas at a fixed temperature and pressure in a uniform gravitational field, the heights of the various molecules also follow an approximate exponential distribution. This is a consequence of the entropy property mentioned below.
Properties
Mean and variance
The mean or expected value of an exponentially distributed random variable X with rate parameter λ is given by
![\mathrm{E}[X] = \frac{1}{\lambda}. \!](../../images/77/7761.png)
In light of the examples given above, this makes sense: if you receive phone calls at an average rate of 2 per hour, then you can expect to wait half an hour for every call.
The variance of X is given by
![\mathrm{Var}[X] = \frac{1}{\lambda^2}. \!](../../images/77/7762.png)
Memorylessness
An important property of the exponential distribution is that it is memoryless. This means that if a random variable T is exponentially distributed, its conditional probability obeys
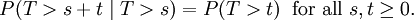
This says that the conditional probability that we need to wait, for example, more than another 10 seconds before the first arrival, given that the first arrival has not yet happened after 30 seconds, is no different from the initial probability that we need to wait more than 10 seconds for the first arrival. This is often misunderstood by students taking courses on probability: the fact that P(T > 40 | T > 30) = P(T > 10) does not mean that the events T > 40 and T > 30 are independent. To summarize: "memorylessness" of the probability distribution of the waiting time T until the first arrival means
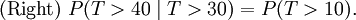
It does not mean
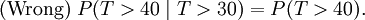
(That would be independence. These two events are not independent.)
The exponential distributions and the geometric distributions are the only memoryless probability distributions.
The exponential distribution also has a constant hazard function.
Quartiles
The quantile function (inverse cumulative distribution function) for Exponential(λ) is
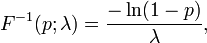
for 0 ≤ p < 1. The quartiles are therefore:
- first quartile
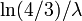
- median
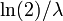
- third quartile
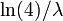
Kullback-Leibler divergence
The directed Kullback-Leibler divergence between Exp(λ0) ('true' distribution) and Exp(λ) ('approximating' distribution) is given by
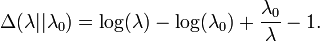
Maximum entropy distribution
Among all continuous probability distributions with support [0,∞) and mean μ, the exponential distribution with λ = 1/μ has the largest entropy.
Distribution of the minimum of exponential random variables
Let X1, ..., Xn be independent exponentially distributed random variables with rate parameters λ1, ..., λn. Then
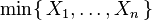
is also exponentially distributed, with parameter
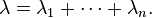
However,
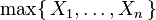
is not exponentially distributed.
Parameter estimation
Suppose you know that a given variable is exponentially distributed and you want to estimate the rate parameter λ.
Maximum likelihood
The likelihood function for λ, given an independent and identically distributed sample x = (x1, ..., xn) drawn from your variable, is
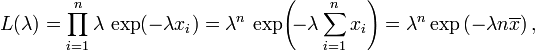
where
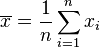
is the sample mean.
The derivative of the likelihood function's logarithm is
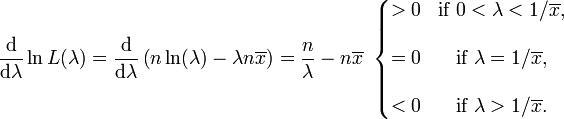
Consequently the maximum likelihood estimate for the rate parameter is
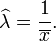
Bayesian inference
The conjugate prior for the exponential distribution is the gamma distribution (of which the exponential distribution is a special case). The following parameterization of the gamma pdf is useful:
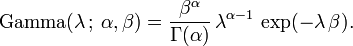
The posterior distribution p can then be expressed in terms of the likelihood function defined above and a gamma prior:
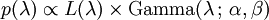
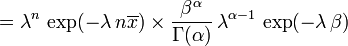
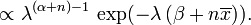
Now the posterior density p has been specified up to a missing normalizing constant. Since it has the form of a gamma pdf, this can easily be filled in, and one obtains
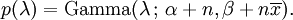
Here the parameter α can be interpreted as the number of prior observations, and β as the sum of the prior observations.
Generating exponential variates
A conceptually very simple method for generating exponential variates is based on inverse transform sampling: Given a random variate U drawn from the uniform distribution on the unit interval 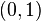 , the variate
, the variate
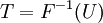
has an exponential distribution, where 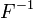 is the quantile function, defined by
is the quantile function, defined by
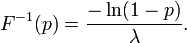
Moreover, if U is uniform on 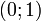 , then so is
, then so is 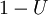 . This means one can generate exponential variates as follows:
. This means one can generate exponential variates as follows:
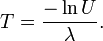
Other methods for generating exponential variates are discussed by Knuth and Devroye.
The ziggurat algorithm is a fast method for generating exponential variates.
Related distributions
- An exponential distribution is a special case of a gamma distribution with
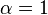 (or
(or 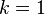 depending on the parameter set used).
depending on the parameter set used). - Both an exponential distribution and a gamma distribution are special cases of the phase-type distribution.
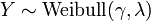 , i.e. Y has a Weibull distribution, if
, i.e. Y has a Weibull distribution, if 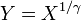 and
and 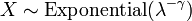 . In particular, every exponential distribution is also a Weibull distribution.
. In particular, every exponential distribution is also a Weibull distribution.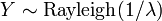 , i.e. Y has a Rayleigh distribution, if
, i.e. Y has a Rayleigh distribution, if 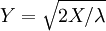 and
and 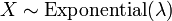 .
.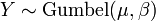 , i.e. Y has a Gumbel distribution if
, i.e. Y has a Gumbel distribution if 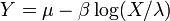 and .
and .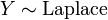 , i.e. Y has a Laplace distribution, if
, i.e. Y has a Laplace distribution, if 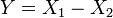 for two independent exponential distributions
for two independent exponential distributions 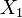 and
and 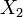 .
.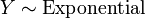 , i.e. Y has an exponential distribution if
, i.e. Y has an exponential distribution if 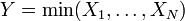 for independent exponential distributions
for independent exponential distributions 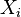 .
.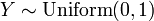 , i.e. Y has a uniform distribution if
, i.e. Y has a uniform distribution if 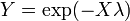 and .
and .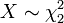 , i.e. X has a chi-square distribution with 2 degrees of freedom, if
, i.e. X has a chi-square distribution with 2 degrees of freedom, if 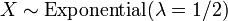 .
.- Let
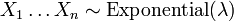 be exponentially distributed and independent and
be exponentially distributed and independent and 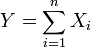 . Then
. Then 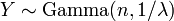
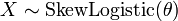 , then
, then