
Arithmetic mean
About this schools Wikipedia selection
Arranging a Wikipedia selection for schools in the developing world without internet was an initiative by SOS Children. Child sponsorship helps children one by one http://www.sponsor-a-child.org.uk/.
In mathematics and statistics, the arithmetic mean (or simply the mean) of a list of numbers is the sum of all the members of the list divided by the number of items in the list. If the list is a statistical population, then the mean of that population is called a population mean. If the list is a statistical sample, we call the resulting statistic a sample mean.
The mean is the most commonly-used type of average and is often referred to simply as the average. The term "mean" or "arithmetic mean" is preferred in mathematics and statistics to distinguish it from other averages such as the median and the mode.
Introduction
If we denote a set of data by X = (x1, x2, ..., xn), then the sample mean is typically denoted with a horizontal bar over the variable (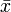 , enunciated "x bar").
, enunciated "x bar").
The symbol μ (Greek: mu) is used to denote the arithmetic mean of an entire population. Or, for a random number that has a defined mean, μ is the probabilistic mean or expected value of the random number. If the set X is a collection of random numbers with probabilistic mean of μ, then for any individual sample, xi, from that collection, μ = E{xi} is the expected value of that sample.
In practice, the difference between μ and is that μ is typically unobservable because one observes only a sample rather than the whole population, and if the sample is drawn randomly, then one may treat , but not μ, as a random variable, attributing a probability distribution to it (the sampling distribution of the mean).
Both are computed in the same way:
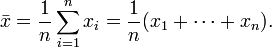
If X is a random variable, then the expected value of X can be seen as the long-term arithmetic mean that occurs on repeated measurements of X. This is the content of the law of large numbers. As a result, the sample mean is used to estimate unknown expected values.
Note that several other "means" have been defined, including the generalized mean, the generalized f-mean, the harmonic mean, the arithmetic-geometric mean, and various weighted means.
Examples
- If you have 3 numbers then add them and divide them by 3:
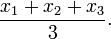
- If you have 4 numbers add them and divide by 4:
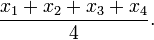
Problems with some uses of the mean
While the mean is often used to report central tendency, it may not be appropriate for describing skewed distributions, because it is easily misinterpreted. The arithmetic mean is greatly influenced by outliers. These distortions can occur when the mean is different from the median. When this happens the median may be a better description of central tendency.
A classic example is average income. The arithmetic mean may be misinterpreted to imply that most people's incomes are higher than is in fact the case. When presented with an "average" one may be led to believe that most people's incomes are near this number. This "average" (arithmetic mean) income is higher than most people's incomes, because high income outliers skew the result higher (in contrast, the median income "resists" such skew). However, this "average" says nothing about the number of people near the median income (nor does it say anything about the modal income that most people are near). Nevertheless, because one might carelessly relate "average" and "most people" one might incorrectly assume that most people's incomes would be higher (nearer this inflated "average") than they are. For instance, reporting the "average" net worth in Medina, Washington as the arithmetic mean of all annual net worths would yield a surprisingly high number because of Bill Gates. Consider the scores (1, 2, 2, 2, 3, 9). The arithmetic mean is 3.17, but five out of six scores are below this.
In certain situations, the arithmetic mean is the wrong measure of central tendency altogether. For example, if a stock fell 10 % in the first year, and rose 30 % in the second year, then it would be incorrect to report its "average" increase per year over this two year period as the arithmetic mean (−10 % + 30 %)/2 = 10 %; the correct average in this case is the geometric mean which yields an average increase per year of only 8.2 %. The reason for this is that each of those percents have different starting points. If the stock starts at $30 and falls 10 %, it is now at $27. If the stock then rises 30 %, it is now $35.1. The arithmetic mean of those rises is 10 %, but since the stock rose by $5.1 in 2 years, an average of 8.2 % would result in the final $35.1 figure [$30(1-10 %)(1+30 %) = $30(1+8.2 %)(1+8.2 %) = $35.1]. If one used the arithmetic mean 10 % in the same way, one would not get the actual increase [$30(1+10 %)(1+10 %) = $36.3].
Particular care must be taken when using cyclic data such as phases or angles. Taking the arithmetic mean of 1 degree and 359 degrees yields a result of 180 degrees, whereas 1 and 359 are both adjacent to 360 degrees which may be a more correct average value. In general application such an oversight will lead to the average value artificially moving towards the middle of the numerical range. A solution to this problem is to use the optimization formulation, and redefine the difference as a modular distance.