
Numerical integration
Background Information
This Wikipedia selection is available offline from SOS Children for distribution in the developing world. Visit the SOS Children website at http://www.soschildren.org/

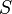
In numerical analysis, numerical integration constitutes a broad family of algorithms for calculating the numerical value of a definite integral, and by extension, the term is also sometimes used to describe the numerical solution of differential equations. This article focuses on calculation of definite integrals. The term numerical quadrature (often abbreviated to quadrature) is more or less a synonym for numerical integration, especially as applied to one-dimensional integrals. Numerical integration over more than one dimension is sometimes described as cubature, although the meaning of quadrature is understood for higher dimensional integration as well.
The basic problem considered by numerical integration is to compute an approximate solution to a definite integral:
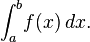
If f(x) is a smooth well-behaved function, integrated over a small number of dimensions and the limits of integration are bounded, there are many methods of approximating the integral with arbitrary precision.
Reasons for numerical integration
There are several reasons for carrying out numerical integration. The integrand f(x) may be known only at certain points, such as obtained by sampling. Some embedded systems and other computer applications may need numerical integration for this reason.
A formula for the integrand may be known, but it may be difficult or impossible to find an antiderivative which is an elementary function. An example of such an integrand is f(x) = exp(−x2), the antiderivative of which (the error function, times a constant) cannot be written in elementary form.
It may be possible to find an antiderivative symbolically, but it may be easier to compute a numerical approximation than to compute the antiderivative. That may be the case if the antiderivative is given as an infinite series or product, or if its evaluation requires a special function which is not available.
Methods for one-dimensional integrals
Numerical integration methods can generally be described as combining evaluations of the integrand to get an approximation to the integral. The integrand is evaluated at a finite set of points called integration points and a weighted sum of these values is used to approximate the integral. The integration points and weights depend on the specific method used and the accuracy required from the approximation.
An important part of the analysis of any numerical integration method is to study the behaviour of the approximation error as a function of the number of integrand evaluations. A method which yields a small error for a small number of evaluations is usually considered superior. Reducing the number of evaluations of the integrand reduces the number of arithmetic operations involved, and therefore reduces the total round-off error. Also, each evaluation takes time, and the integrand may be arbitrarily complicated.
A 'brute force' kind of numerical integration can be done, if the integrand is reasonably well-behaved (i.e. piecewise continuous and of bounded variation), by evaluating the integrand with very small increments.
Quadrature rules based on interpolating functions
A large class of quadrature rules can be derived by constructing interpolating functions which are easy to integrate. Typically these interpolating functions are polynomials.

The simplest method of this type is to let the interpolating function be a constant function (a polynomial of degree zero) which passes through the point ((a+b)/2, f((a+b)/2)). This is called the midpoint rule or rectangle rule.
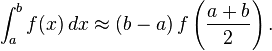

The interpolating function may be an affine function (a polynomial of degree 1) which passes through the points (a, f(a)) and (b, f(b)). This is called the trapezoidal rule.
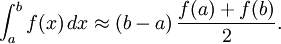

For either one of these rules, we can make a more accurate approximation by breaking up the interval [a, b] into some number n of subintervals, computing an approximation for each subinterval, then adding up all the results. This is called a composite rule, extended rule, or iterated rule. For example, the composite trapezoidal rule can be stated as
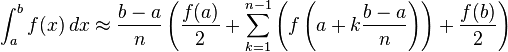
where the subintervals have the form [k h, (k+1) h], with h = (b−a)/n and k = 0, 1, 2, ..., n−1.
Interpolation with polynomials evaluated at equally spaced points in [a, b] yields the Newton–Cotes formulas, of which the rectangle rule and the trapezoidal rule are examples. Simpson's rule, which is based on a polynomial of order 2, is also a Newton–Cotes formula.
Quadrature rules with equally spaced points have the very convenient property of nesting. The corresponding rule with each interval subdivided includes all the current points, so those integrand values can be re-used.
If we allow the intervals between interpolation points to vary, we find another group of quadrature formulas, such as the Gaussian quadrature formulas. A Gaussian quadrature rule is typically more accurate than a Newton–Cotes rule which requires the same number of function evaluations, if the integrand is smooth (i.e., if it is sufficiently differentiable). Other quadrature methods with varying intervals include Clenshaw–Curtis quadrature (also called Fejér quadrature) methods, which do nest.
Gaussian quadrature rules do not nest, but the related Gauss–Kronrod quadrature formulas do.
Adaptive algorithms
If f(x) does not have many derivatives at all points, or if the derivatives become large, then Gaussian quadrature is often insufficient. In this case, an algorithm similar to the following will perform better:
def calculate_definite_integral_of_f(f, initial_step_size): ''' This algorithm calculates the definite integral of a function from 0 to 1, adaptively, by choosing smaller steps near problematic points. ''' x = 0.0 h = initial_step_size accumulator = 0.0 while x < 1.0: if x + h > 1.0: h = 1.0 - x quad_this_step = if error_too_big_in_quadrature_of_over_range(f, [x,x+h]): h = make_h_smaller(h) else: accumulator += quadrature_of_f_over_range(f, [x,x+h]) x += h if error_too_small_in_quadrature_of_over_range(f, [x,x+h]): h = make_h_larger(h) # Avoid wasting time on tiny steps. return accumulator
Some details of the algorithm require careful thought. For many cases, estimating the error from quadrature over an interval for a function f(x) isn't obvious. One popular solution is to use two different rules of quadrature, and use their difference as an estimate of the error from quadrature. The other problem is deciding what "too large" or "very small" signify. A local criterion for "too large" is that the quadrature error should not be larger than t · h where t, a real number, is the tolerance we wish to set for global error. Then again, if h is already tiny, it may not be worthwhile to make it even smaller even if the quadrature error is apparently large. A global criterion is that the sum of errors on all the intervals should be less than t. This type of error analysis is usually called "a posteriori" since we compute the error after having computed the approximation.
Heuristics for adaptive quadrature are discussed by Forsythe et al. (Section 5.4).
Extrapolation methods
The accuracy of a quadrature rule of the Newton-Cotes type is generally a function of the number of evaluation points. The result is usually more accurate as number of evaluation points increases, or, equivalently, as the width of the step size between the points decreases. It is natural to ask what the result would be if the step size were allowed to approach zero. This can be answered by extrapolating the result from two or more nonzero step sizes, using series acceleration methods such as Richardson extrapolation. The extrapolation function may be a polynomial or rational function. Extrapolation methods are described in more detail by Stoer and Bulirsch (Section 3.4) and are implemented in many of the routines in the QUADPACK library.
Conservative (a priori) error estimation
Let f have a bounded first derivative over [a,b]. The mean value theorem for f, where x < b, gives
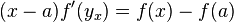
for some yx in [a,x] depending on x. If we integrate in x from a to b on both sides and take the absolute values, we obtain
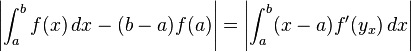
We can further approximate the integral on the right-hand side by bringing the absolute value into the integrand, and replacing the term in f' by an upper bound:
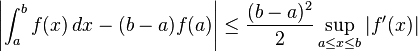 (**)
(**)
(See supremum.) Hence, if we approximate the integral ∫ab f(x) dx by the quadrature rule (b − a)f(a) our error is no greater than the right hand side of (**). We can convert this into an error analysis for the Riemann sum (*), giving an upper bound of
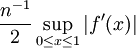
for the error term of that particular approximation. (Note that this is precisely the error we calculated for the example 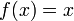 .) Using more derivatives, and by tweaking the quadrature, we can do a similar error analysis using a Taylor series (using a partial sum with remainder term) for f. This error analysis gives a strict upper bound on the error, if the derivatives of f are available.
.) Using more derivatives, and by tweaking the quadrature, we can do a similar error analysis using a Taylor series (using a partial sum with remainder term) for f. This error analysis gives a strict upper bound on the error, if the derivatives of f are available.
This integration method can be combined with interval arithmetic to produce computer proofs and verified calculations.
Integrals over infinite intervals
Infinite intervals
One way to calculate an integral over infinite interval,
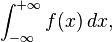
is to transform it into an integral over a finite interval by any one of several possible changes of variables, for example:
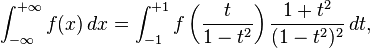
The integral over finite interval can then be evaluated by ordinary integration methods.
Half-infinite intervals
An integral over a half-infinite interval can likewise be transformed into an integral over a finite interval by any one of several possible changes of variables, for example:
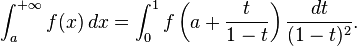
Similarly,
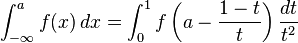
Multidimensional integrals
The quadrature rules discussed so far are all designed to compute one-dimensional integrals. To compute integrals in multiple dimensions, one approach is to phrase the multiple integral as repeated one-dimensional integrals by appealing to Fubini's theorem. This approach requires the function evaluations to grow exponentially as the number of dimensions increases. Two methods are known to overcome this so-called curse of dimensionality.
Monte Carlo
Monte Carlo methods and quasi-Monte Carlo methods are easy to apply to multi-dimensional integrals, and may yield greater accuracy for the same number of function evaluations than repeated integrations using one-dimensional methods.
A large class of useful Monte Carlo methods are the so-called Markov chain Monte Carlo algorithms, which include the Metropolis-Hastings algorithm and Gibbs sampling.
Sparse grids
Sparse grids were originally developed by Smolyak for the quadrature of high dimensional functions. The method is always based on a one dimensional quadrature rule, but performs a more sophisticated combination of univariate results.
Connection with differential equations
The problem of evaluating the integral
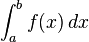
can be reduced to an initial value problem for an ordinary differential equation. If the above integral is denoted by I(b), then the function I satisfies
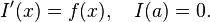
Methods developed for ordinary differential equations, such as Runge–Kutta methods, can be applied to the restated problem and thus be used to evaluate the integral. For instance, the standard fourth-order Runge–Kutta method applied to the differential equation yields Simpson's rule from above.
The differential equation I ' (x) = ƒ(x) has a special form: the right-hand side contains only the dependent variable (here x) and not the independent variable (here I). This simplifies the theory and algorithms considerably. The problem of evaluating integrals is thus best studied in its own right.