
Bayesian inference
About this schools Wikipedia selection
This Schools selection was originally chosen by SOS Children for schools in the developing world without internet access. It is available as a intranet download. A quick link for child sponsorship is http://www.sponsor-a-child.org.uk/
Bayesian inference is statistical inference in which evidence or observations are used to update or to newly infer the probability that a hypothesis may be true. The name "Bayesian" comes from the frequent use of Bayes' theorem in the inference process. Bayes' theorem was derived from the work of the Reverend Thomas Bayes.
Evidence and changing beliefs
Bayesian inference uses aspects of the scientific method, which involves collecting evidence that is meant to be consistent or inconsistent with a given hypothesis. As evidence accumulates, the degree of belief in a hypothesis ought to change. With enough evidence, it should become very high or very low. Thus, proponents of Bayesian inference say that it can be used to discriminate between conflicting hypotheses: hypotheses with very high support should be accepted as true and those with very low support should be rejected as false. However, detractors say that this inference method may be biased due to initial beliefs that one needs to hold before any evidence is ever collected.
Bayesian inference uses a numerical estimate of the degree of belief in a hypothesis before evidence has been observed and calculates a numerical estimate of the degree of belief in the hypothesis after evidence has been observed. Bayesian inference usually relies on degrees of belief, or subjective probabilities, in the induction process and does not necessarily claim to provide an objective method of induction. Nonetheless, some Bayesian statisticians believe probabilities can have an objective value and therefore Bayesian inference can provide an objective method of induction. See scientific method.
Bayes' theorem adjusts probabilities given new evidence in the following way:
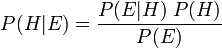
where
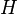 represents a specific hypothesis, which may or may not be some null hypothesis.
represents a specific hypothesis, which may or may not be some null hypothesis.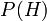 is called the prior probability of that was inferred before new evidence,
is called the prior probability of that was inferred before new evidence, 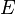 , became available.
, became available.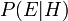 is called the conditional probability of seeing the evidence if the hypothesis happens to be true. It is also called a likelihood function when it is considered as a function of for fixed .
is called the conditional probability of seeing the evidence if the hypothesis happens to be true. It is also called a likelihood function when it is considered as a function of for fixed .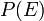 is called the marginal probability of : the a priori probability of witnessing the new evidence under all possible hypotheses. It can be calculated as the sum of the product of all probabilities of any complete set of mutually exclusive hypotheses and corresponding conditional probabilities:
is called the marginal probability of : the a priori probability of witnessing the new evidence under all possible hypotheses. It can be calculated as the sum of the product of all probabilities of any complete set of mutually exclusive hypotheses and corresponding conditional probabilities: 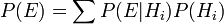 .
.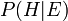 is called the posterior probability of given .
is called the posterior probability of given .
The factor 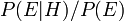 represents the impact that the evidence has on the belief in the hypothesis. If it is likely that the evidence would be observed when the hypothesis under consideration is true, but unlikely that would have been the outcome of the observation, then this factor will be large. Multiplying the prior probability of the hypothesis by this factor would result in a larger posterior probability of the hypothesis given the evidence. Conversely, if it is unlikely that the evidence would be observed if the hypothesis under consideration is true, but a priori likely that would be observed, then the factor would reduce the posterior probability for . Under Bayesian inference, Bayes' theorem therefore measures how much new evidence should alter a belief in a hypothesis.
represents the impact that the evidence has on the belief in the hypothesis. If it is likely that the evidence would be observed when the hypothesis under consideration is true, but unlikely that would have been the outcome of the observation, then this factor will be large. Multiplying the prior probability of the hypothesis by this factor would result in a larger posterior probability of the hypothesis given the evidence. Conversely, if it is unlikely that the evidence would be observed if the hypothesis under consideration is true, but a priori likely that would be observed, then the factor would reduce the posterior probability for . Under Bayesian inference, Bayes' theorem therefore measures how much new evidence should alter a belief in a hypothesis.
Bayesian statisticians argue that even when people have very different prior subjective probabilities, new evidence from repeated observations will tend to bring their posterior subjective probabilities closer together. However, others argue that when people hold widely different prior subjective probabilities their posterior subjective probabilities may never converge even with repeated collection of evidence. These critics argue that worldviews which are completely different initially can remain completely different over time despite a large accumulation of evidence.
Multiplying the prior probability by the factor will never yield a probability that is greater than 1, since is at least as great as 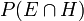 (where
(where 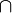 denotes "and"), which equals
denotes "and"), which equals 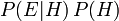 (see joint probability).
(see joint probability).
The probability of given , , can be represented as a function of its second argument with its first argument held fixed. Such a function is called a likelihood function; it is a function of alone, with treated as a parameter. A ratio of two likelihood functions is called a likelihood ratio, 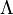 . For example,
. For example,
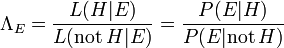 ,
,
where the dependence of 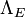 on is suppressed for simplicity (as might have been, except we will need to use that parameter below).
on is suppressed for simplicity (as might have been, except we will need to use that parameter below).
Since and not- are mutually exclusive and span all possibilities, the sum previously given for the marginal probability reduces to 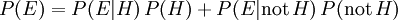 . As a result, we can rewrite Bayes' theorem as
. As a result, we can rewrite Bayes' theorem as
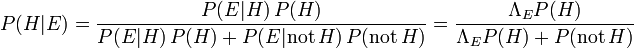 .
.
We could then exploit the identity 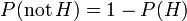 to exhibit as a function of just (and , which is computed directly from the evidence).
to exhibit as a function of just (and , which is computed directly from the evidence).
With two independent pieces of evidence 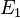 and
and 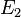 , Bayesian inference can be applied iteratively. We could use the first piece of evidence to calculate an initial posterior probability, and then use that posterior probability as a new prior probability to calculate a second posterior probability given the second piece of evidence. Bayes' theorem applied iteratively yields
, Bayesian inference can be applied iteratively. We could use the first piece of evidence to calculate an initial posterior probability, and then use that posterior probability as a new prior probability to calculate a second posterior probability given the second piece of evidence. Bayes' theorem applied iteratively yields
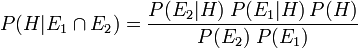
Using likelihood ratios, we find that
![P(H|E_1 \cap E_2) = \frac{\Lambda_1 \Lambda_2 P(H)}{[\Lambda_1 P(H) + P(\mathrm{not}\,H)]\;[\Lambda_2 P(H) + P(\mathrm{not}\,H)]}](../../images/180/18071.png) ,
,
This iteration of Bayesian inference could be extended with more independent pieces of evidence.
Bayesian inference is used to calculate probabilities for decision making under uncertainty. Besides the probabilities, a loss function should be evaluated to take into account the relative impact of the alternatives.
Simple examples of Bayesian inference
From which bowl is the cookie?
To illustrate, suppose there are two full bowls of cookies. Bowl #1 has 10 chocolate chip and 30 plain cookies, while bowl #2 has 20 of each. Our friend Fred picks a bowl at random, and then picks a cookie at random. We may assume there is no reason to believe Fred treats one bowl differently from another, likewise for the cookies. The cookie turns out to be a plain one. How probable is it that Fred picked it out of bowl #1?
Intuitively, it seems clear that the answer should be more than a half, since there are more plain cookies in bowl #1. The precise answer is given by Bayes' theorem. Let 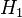 correspond to bowl #1, and
correspond to bowl #1, and 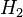 to bowl #2. It is given that the bowls are identical from Fred's point of view, thus
to bowl #2. It is given that the bowls are identical from Fred's point of view, thus 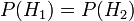 , and the two must add up to 1, so both are equal to 0.5. The event is the observation of a plain cookie. From the contents of the bowls, we know that
, and the two must add up to 1, so both are equal to 0.5. The event is the observation of a plain cookie. From the contents of the bowls, we know that 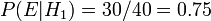 and
and 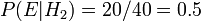 . Bayes' formula then yields
. Bayes' formula then yields
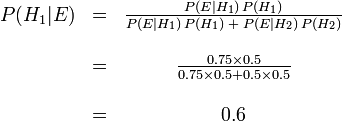
Before we observed the cookie, the probability we assigned for Fred having chosen bowl #1 was the prior probability, 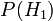 , which was 0.5. After observing the cookie, we must revise the probability to
, which was 0.5. After observing the cookie, we must revise the probability to 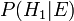 , which is 0.6.
, which is 0.6.
False positives in a medical test
False positives result when a test falsely or incorrectly reports a positive result. For example, a medical test for a disease may return a positive result indicating that patient has a disease even if the patient does not have the disease. We can use Bayes' theorem to determine the probability that a positive result is in fact a false positive. We find that if a disease is rare, then the majority of positive results may be false positives, even if the test is accurate.
Suppose that a test for a disease generates the following results:
- If a tested patient has the disease, the test returns a positive result 99% of the time, or with probability 0.99
- If a tested patient does not have the disease, the test returns a positive result 5% of the time, or with probability 0.05.
Naively, one might think that only 5% of positive test results are false, but that is quite wrong, as we shall see.
Suppose that only 0.1% of the population has that disease, so that a randomly selected patient has a 0.001 prior probability of having the disease.
We can use Bayes' theorem to calculate the probability that a positive test result is a false positive.
Let A represent the condition in which the patient has the disease, and B represent the evidence of a positive test result. Then, probability that the patient actually has the disease given the positive test result is
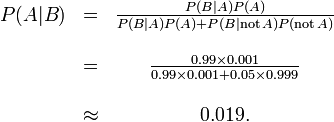
and hence the probability that a positive result is a false positive is about 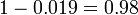 , or 98%.
, or 98%.
Despite the apparent high accuracy of the test, the incidence of the disease is so low that the vast majority of patients who test positive do not have the disease. Nonetheless, the fraction of patients who test positive who do have the disease (.019) is 19 times the fraction of people who have not yet taken the test who have the disease (.001). Thus the test is not useless, and re-testing may improve the reliability of the result.
In order to reduce the problem of false positives, a test should be very accurate in reporting a negative result when the patient does not have the disease. If the test reported a negative result in patients without the disease with probability 0.999, then
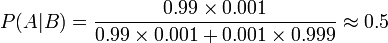 ,
,
so that 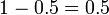 now is the probability of a false positive.
now is the probability of a false positive.
On the other hand, false negatives result when a test falsely or incorrectly reports a negative result. For example, a medical test for a disease may return a negative result indicating that patient does not have a disease even though the patient actually has the disease. We can also use Bayes' theorem to calculate the probability of a false negative. In the first example above,
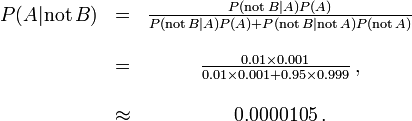
The probability that a negative result is a false negative is about 0.0000105 or 0.00105%. When a disease is rare, false negatives will not be a major problem with the test.
But if 60% of the population had the disease, then the probability of a false negative would be greater. With the above test, the probability of a false negative would be
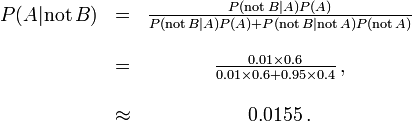
The probability that a negative result is a false negative rises to 0.0155 or 1.55%.
In the courtroom
Bayesian inference can be used in a court setting by an individual juror to coherently accumulate the evidence for and against the guilt of the defendant, and to see whether, in totality, it meets their personal threshold for 'beyond a reasonable doubt'.
- Let
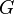 denote the event that the defendant is guilty.
denote the event that the defendant is guilty.
- Let denote the event that the defendant's DNA matches DNA found at the crime scene.
- Let
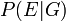 denote the probability of seeing event if the defendant actually is guilty. (Usually this would be taken to be unity.)
denote the probability of seeing event if the defendant actually is guilty. (Usually this would be taken to be unity.)
- Let
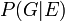 denote the probability that the defendant is guilty assuming the DNA match (event ).
denote the probability that the defendant is guilty assuming the DNA match (event ).
- Let
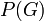 denote the juror's personal estimate of the probability that the defendant is guilty, based on the evidence other than the DNA match. This could be based on his responses under questioning, or previously presented evidence.
denote the juror's personal estimate of the probability that the defendant is guilty, based on the evidence other than the DNA match. This could be based on his responses under questioning, or previously presented evidence.
Bayesian inference tells us that if we can assign a probability p(G) to the defendant's guilt before we take the DNA evidence into account, then we can revise this probability to the conditional probability , since
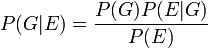
Suppose, on the basis of other evidence, a juror decides that there is a 30% chance that the defendant is guilty. Suppose also that the forensic testimony was that the probability that a person chosen at random would have DNA that matched that at the crime scene is 1 in a million, or 10−6.
The event E can occur in two ways. Either the defendant is guilty (with prior probability 0.3) and thus his DNA is present with probability 1, or he is innocent (with prior probability 0.7) and he is unlucky enough to be one of the 1 in a million matching people.
Thus the juror could coherently revise his opinion to take into account the DNA evidence as follows:
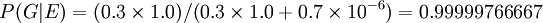 .
.
The benefit of adopting a Bayesian approach is that it gives the juror a formal mechanism for combining the evidence presented. The approach can be applied successively to all the pieces of evidence presented in court, with the posterior from one stage becoming the prior for the next.
The juror would still have to have a prior estimate for the guilt probability before the first piece of evidence is considered. It has been suggested that this could reasonably be the guilt probability of a random person taken from the qualifying population. Thus, for a crime known to have been committed by an adult male living in a town containing 50,000 adult males, the appropriate initial prior probability might be 1/50,000.

For the purpose of explaining Bayes' theorem to jurors, it will usually be appropriate to give it in the form of betting odds rather than probabilities, as these are more widely understood. In this form Bayes' theorem states that
- Posterior odds = prior odds x Bayes factor
In the example above, the juror who has a prior probability of 0.3 for the defendant being guilty would now express that in the form of odds of 3:7 in favour of the defendant being guilty, the Bayes factor is one million, and the resulting posterior odds are 3 million to 7 or about 429,000 to one in favour of guilt.
A logarithmic approach which replaces multiplication with addition and reduces the range of the numbers involved might be easier for a jury to handle. This approach, developed by Alan Turing during World War II and later promoted by I. J. Good and E. T. Jaynes among others, amounts to the use of information entropy.
In the United Kingdom, Bayes' theorem was explained to the jury in the odds form by a statistician expert witness in the rape case of Regina versus Denis John Adams. A conviction was secured but the case went to Appeal, as no means of accumulating evidence had been provided for those jurors who did not want to use Bayes' theorem. The Court of Appeal upheld the conviction, but also gave their opinion that "To introduce Bayes' Theorem, or any similar method, into a criminal trial plunges the Jury into inappropriate and unnecessary realms of theory and complexity, deflecting them from their proper task." No further appeal was allowed and the issue of Bayesian assessment of forensic DNA data remains controversial.
Gardner-Medwin argues that the criterion on which a verdict in a criminal trial should be based is not the probability of guilt, but rather the probability of the evidence, given that the defendant is innocent (akin to a frequentist p-value). He argues that if the posterior probability of guilt is to be computed by Bayes' theorem, the prior probability of guilt must be known. This will depend on the incidence of the crime, which is an unusual piece of evidence to consider in a criminal trial. Consider the following three propositions:
A: The known facts and testimony could have arisen if the defendant is guilty,
B: The known facts and testimony could have arisen if the defendant is innocent,
C: The defendant is guilty.
Gardner-Medwin argues that the jury should believe both A and not-B in order to convict. A and not-B implies the truth of C, but the reverse is not true. It is possible that B and C are both true, but in this case he argues that a jury should acquit, even though they know that they will be letting some guilty people go free. See also Lindley's paradox.
Other court cases in which probabilistic arguments played some role were the Howland will forgery trial, the Sally Clark case, and the Lucia de Berk case.
Search theory
In May 1968 the US nuclear submarine Scorpion (SSN-589) failed to arrive as expected at her home port of Norfolk, Virginia. The US Navy was convinced that the vessel had been lost off the Eastern seaboard but an extensive search failed to discover the wreck. The US Navy's deep water expert, John Craven USN, believed that it was elsewhere and he organised a search south west of the Azores based on a controversial approximate triangulation by hydrophones. He was allocated only a single ship, the Mizar, and he took advice from a firm of consultant mathematicians in order to maximise his resources. A Bayesian search methodology was adopted. Experienced submarine commanders were interviewed to construct hypotheses about what could have caused the loss of the Scorpion.
The sea area was divided up into grid squares and a probability assigned to each square, under each of the hypotheses, to give a number of probability grids, one for each hypothesis. These were then added together to produce an overall probability grid. The probability attached to each square was then the probability that the wreck was in that square. A second grid was constructed with probabilities that represented the probability of successfully finding the wreck if that square were to be searched and the wreck were to be actually there. This was a known function of water depth. The result of combining this grid with the previous grid is a grid which gives the probability of finding the wreck in each grid square of the sea if it were to be searched.
This sea grid was systematically searched in a manner which started with the high probability regions first and worked down to the low probability regions last. Each time a grid square was searched and found to be empty its probability was reassessed using Bayes' theorem. This then forced the probabilities of all the other grid squares to be reassessed (upwards), also by Bayes' theorem. The use of this approach was a major computational challenge for the time but it was eventually successful and the Scorpion was found about 740 kilometers southwest of the Azores in October of that year. Suppose a grid square has a probability p of containing the wreck and that the probability of successfully detecting the wreck if it is there is q. If the square is searched and no wreck is found, then, by Bayes' theorem, the revised probability of the wreck being in the square is given by
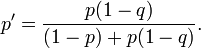
More mathematical examples
Naive Bayes classifier
See naive Bayes classifier.
Posterior distribution of the binomial parameter
In this example we consider the computation of the posterior distribution for the binomial parameter. This is the same problem considered by Bayes in Proposition 9 of his essay.
We are given m observed successes and n observed failures in a binomial experiment. The experiment may be tossing a coin, drawing a ball from an urn, or asking someone their opinion, among many other possibilities. What we know about the parameter (let's call it a) is stated as the prior distribution, p(a).
For a given value of a, the probability of m successes in m+n trials is
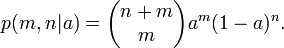
Since m and n are fixed, and a is unknown, this is a likelihood function for a. From the continuous form of the law of total probability we have
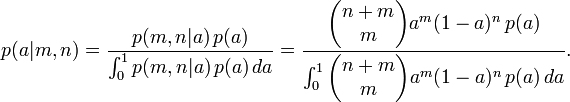
For some special choices of the prior distribution p(a), the integral can be solved and the posterior takes a convenient form. In particular, if p(a) is a beta distribution with parameters m0 and n0, then the posterior is also a beta distribution with parameters m+m0 and n+n0.
A conjugate prior is a prior distribution, such as the beta distribution in the above example, which has the property that the posterior is the same type of distribution.
What is "Bayesian" about Proposition 9 is that Bayes presented it as a probability for the parameter a. That is, not only can one compute probabilities for experimental outcomes, but also for the parameter which governs them, and the same algebra is used to make inferences of either kind. Interestingly, Bayes actually states his question in a way that might make the idea of assigning a probability distribution to a parameter palatable to a frequentist. He supposes that a billiard ball is thrown at random onto a billiard table, and that the probabilities p and q are the probabilities that subsequent billiard balls will fall above or below the first ball. By making the binomial parameter a depend on a random event, he cleverly escapes a philosophical quagmire that was an issue he most likely was not even aware of.
Computer applications
Bayesian inference has applications in artificial intelligence and expert systems. Bayesian inference techniques have been a fundamental part of computerized pattern recognition techniques since the late 1950s. There is also an ever growing connection between Bayesian methods and simulation-based Monte Carlo techniques since complex models cannot be processed in closed form by a Bayesian analysis, while the graphical model structure inherent to statistical models, may allow for efficient simulation algorithms like the Gibbs sampling and other Metropolis-Hastings algorithm schemes. Recently Bayesian inference has gained popularity amongst the phylogenetics community for these reasons; applications such as BEAST, MrBayes and P4 allow many demographic and evolutionary parameters to be estimated simultaneously.
As applied to statistical classification, Bayesian inference has been used in recent years to develop algorithms for identifying unsolicited bulk e-mail spam. Applications which make use of Bayesian inference for spam filtering include DSPAM, Bogofilter, SpamAssassin, InBoxer, and Mozilla. Spam classification is treated in more detail in the article on the naive Bayes classifier.
In some applications fuzzy logic is an alternative to Bayesian inference. Fuzzy logic and Bayesian inference, however, are mathematically and semantically not compatible: You cannot, in general, understand the degree of truth in fuzzy logic as probability and vice versa.